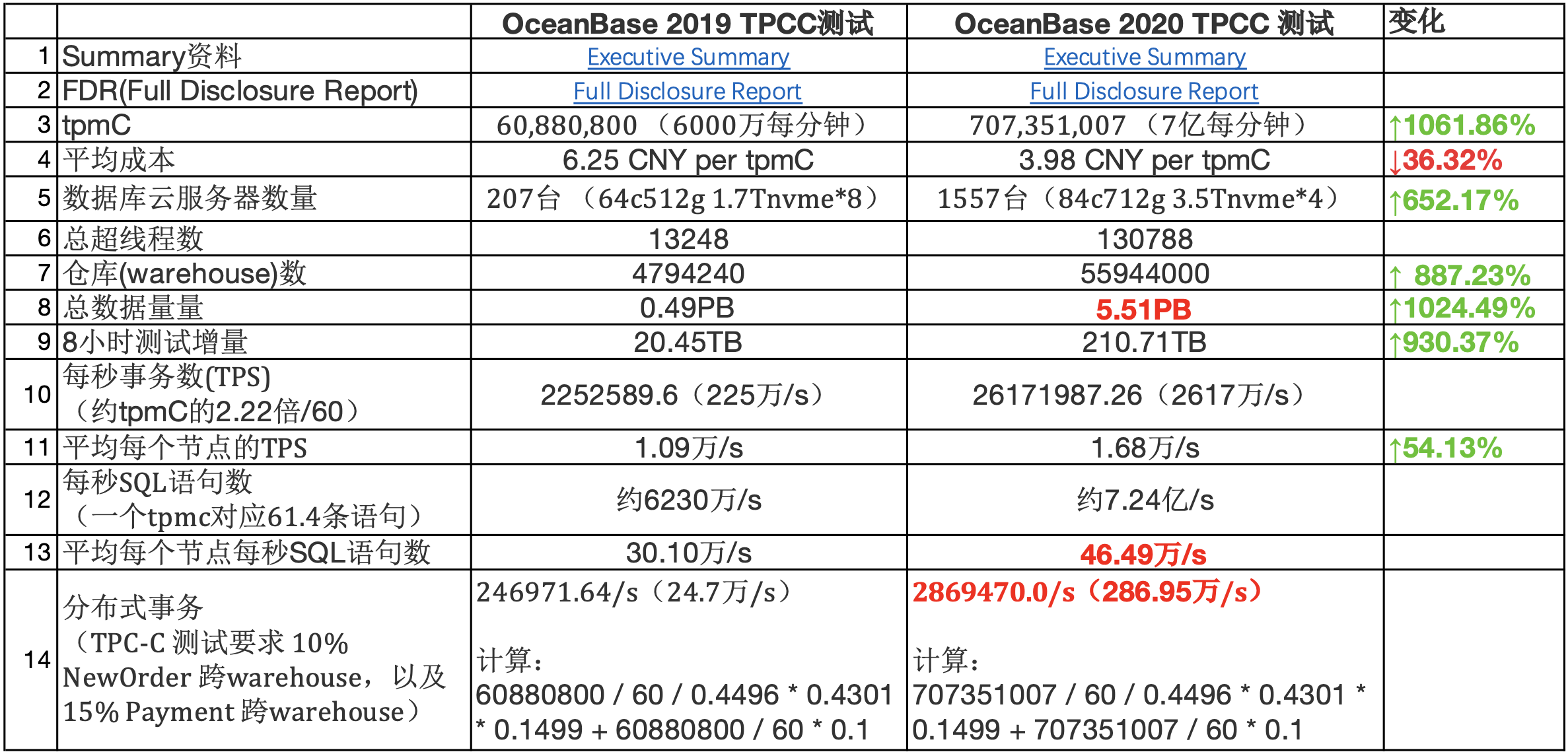
取巧:既然是跑分,OB也在某种程度上利用了规则,以降低硬件成本,不过这是在FDR中明确披露的“All other tables are replicated into 3 replicas: one full replica, one data replica and one log replica that are distributed among database nodes. A full replica contains cardinality, in-memory increments (mutations) that could be checkpointed to disk and redo log of the corresponding table. A data replica contains cardinality, checkpoints of in-memory increments (mutations) and redo log (both from the full replica). A log replica contains redo log only.” 与正常的应用在网站核心业务上3副本5副本的部署方式不同,OB在tpcc的性能测试中,3个副本不是对等的,其中1个完整副本包含redolog,LSM内存表,SST数据,这里隐含的意思是这个副本会做compaction;第2个副本只包含redolog,SST数据,它应该是在主副本完成compaction之后从主副本直接copy sst;第三副本只包含redolog。因此这里可以分析出来:整个1557台节点的内存基本都可以用于事务读写,两个副本基本没有内存开销;整个1557台节点的硬盘,用于存储2份数据文件而不是3份。之所以可以这样,是因为tpcc并没有规定或者考察RTO时间,所以只要保证RPO为零就行了。
P1 脏读 (“Dirty read”): SQL-transaction T1 modifies a row. SQL- transaction T2 then reads that row before T1 performs a COMMIT. If T1 then performs a ROLLBACK, T2 will have read a row that was never committed and that may thus be considered to have never existed.
P2 不可重复读 (“Non-repeatable read”): SQL-transaction T1 reads a row. SQL- transaction T2 then modifies or deletes that row and performs a COMMIT. If T1 then attempts to reread the row, it may receive the modified value or discover that the row has been deleted.
P3 幻读 (“Phantom”): SQL-transaction T1 reads the set of rows N that satisfy some <search condition>. SQL-transaction T2 then executes SQL-statements that generate one or more rows that satisfy the <search condition> used by SQL-transaction T1. If SQL-transaction T1 then repeats the initial read with the same <search condition>, it obtains a different collection of rows.
通过依次禁止这三种异象,ANSI确定了4种标准隔离级别,如下表所示:
级别
P1(脏读)
P2(不可重复读)
P3(幻读)
Read Uncommitted
允许
允许
允许
Read Committed
禁止
允许
允许
Repeatable Read
禁止
禁止
允许
(Anomaly) Serializable
禁止
禁止
禁止
Note: The exclusion of these penomena or SQL-transactions executing at isolation level SERIALIZABLE is a consequence of the requirement that such transactions be serializable.
The execution of concurrent SQL-transactions at isolation level SERIALIZABLE is guaranteed to be serializable. A serializable execution is defined to be an execution of the operations of concurrently executing SQL-transactions that produces the same effect as some serial execution of those same SQL-transactions
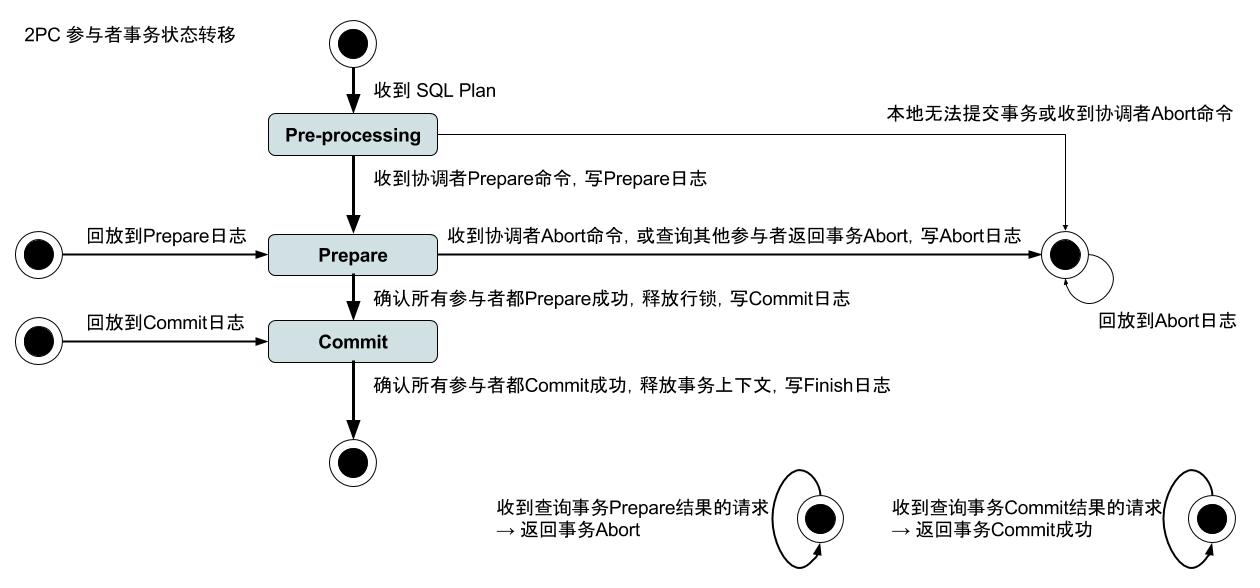
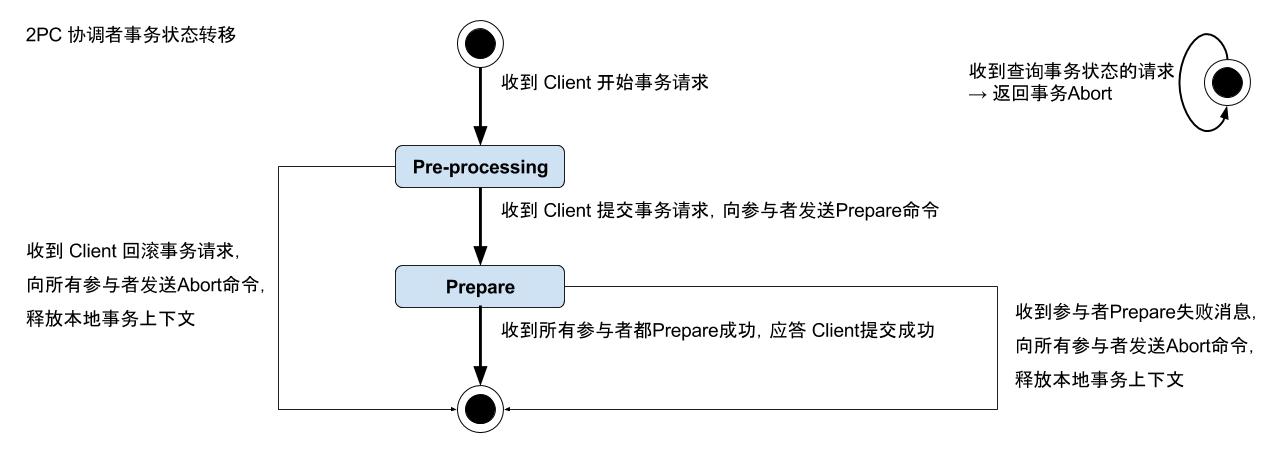
两阶段提交(2 Phase Commit简称2PC)协议是用于在多个节点之间达成一致的通信协议,它是实现“有状态的”分布式系统所必须面对的经典问题之一。本文通过对比经典2PC协议,和Google工程实践的基础上,分析一种优化延迟的2PC协议。为了方便说明,本文主要针对分布式数据库中,跨域sharding的2PC方案的讨论。主要参考文献:Gray J, Lamport L. Consensus on transaction commit[J]. ACM Transactions on Database Systems (TODS), 2006, 31(1): 133-160.