OceanBase在2020年打破自己在2019年创造的记录,第二次问鼎,在最近又引起一波讨论,作为利益相关方(前ob初创团队员工、目前正在现东家做着类似的事情),也想蹭一波热度,来从数据层面分析解读下。
关于tpcc的背景知识,请大家上tpcc官网了解,不要轻信各种公众号文章,顺便贴一下tpcc排名页面(TPC-C排名页面:http://www.tpc.org/tpcc/results/tpcc_results.asp),这里我也顺便列一些关于tpcc几个关键的背景考点:
-
TPCC测试结果是需要委员会认证的,未经官方认证的测试结果并不具备可信性,委员会要在宕机恢复、RTO、RPO、性能波动、软硬件成本等方面进行评审。比如很多国内项目自己公布的TPCC测试结果,并不具备可信性。
-
根据TPCC测试标准,每个warehouse所能获得的tpmC上限是12.86,行业里如果某家厂商自己公布的测试结果算下来平均每个warehouse的tpmC超过12.86,说明它很可能在通过缩减warehouse数量来利用内存优势跑分,这是不符合标准规范的。
-
TPCC只有测试标准文档,没有官方的测试软件,参与评测的各家厂商需要根据标准文档自行开发测试软件。截至2020年,我还没有搜到之前参与过TPCC测试的厂商开源出来的测试工具。
-
事务一致性:TPC-C 测试要求 10% NewOrder 跨warehouse,以及 15% Payment 跨warehouse,除库存分析类的查询外禁止ANSI Isolation Levels中的的P3/P2/P1/P0,即达到Serializable级别,基于中间件的分库分表的系统比较难达到这种事务一致性要求。
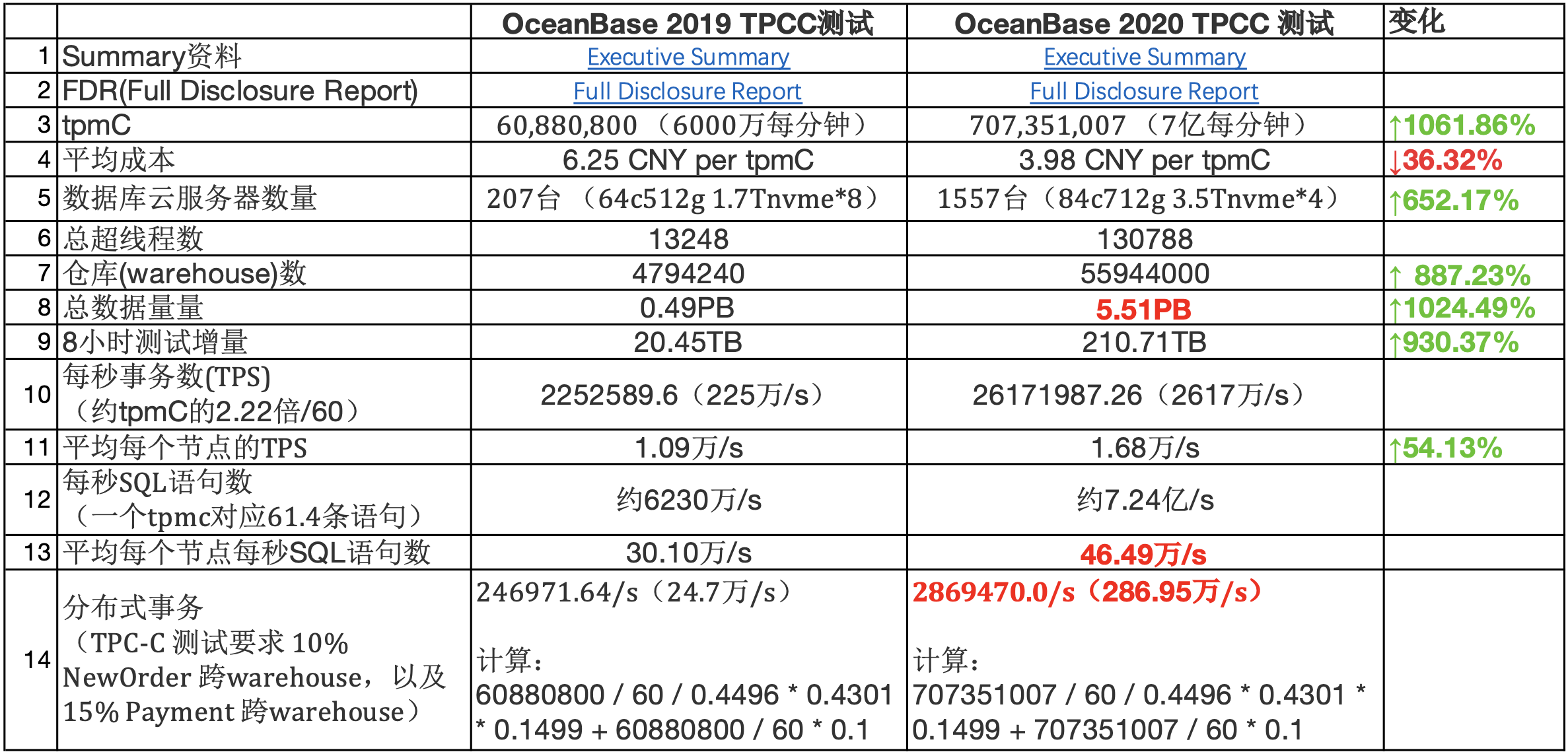
下面对比下OceanBase在2019年和2020年两次tpcc测试结果的数据,列几个值得关注的点:
- 性价比:总的tpmc上涨10倍多,平均成本缺降低36.32%,主要应该是得益于单个节点算力密度的增加,CPU超线程数由64增加到84,内存由512G增加到712G,NVME盘有1.7T增加到3.5T,一般来说单个主机算力密度越高,综合成本越低。
- ScaleOut能力:节点数量由207台增加到1557台,节点数增加652.17%,超线程数增加887.23%,而tpmc增加1061.86%,证明了系统在1600这个规模上的线性scale out能力。而且由于叠加了软件层面的优化,甚至达到超线性的效果。
- 数据规模:数据量由0.49PB增加到5.51PB,从TB级迈入PB级;内存容量在总数据量中占比为19.19%,系统一定会有读盘的请求。不过从tpcc的测试场景来看,对于OB这种LSM引擎还是更加友好的,毕竟占比最大的NewOrder与PayOrder,都有很强的时效性,这两个操作产生的数据应该可以几乎全部命中在内存中,内存使用效率远大于Btree类引擎。
- 单点能力:单个节点的处理能力被优化到极致,SQL语句处理能力达到46.49万/s,这得益于OB事务引擎大量使用无锁结构、完全的池化的内存管理和libeasy框架的高并发处理能力等。考虑到这还是带上了Paxos强同步redolog的场景,已经能把市面上的几个开源数据库按到地上摩擦的抠不出来了。
- 分布式事务:百万级的分布式事务处理能力,从24.7万/s,增加到286.95万/s,前几天好像看到有文章说OB的tpcc测试没有分布式事务,是没有仔细学习tpcc的FRD文档的。分布式事务的优化应该是得益于对Jim Gray和Lamport的合作的一篇文章的工业实现。
- 持久又稳定的输出:持续8个小时测试,吞吐抖动不超过2%,这一点看FDR中的图就行了
- 取巧:既然是跑分,OB也在某种程度上利用了规则,以降低硬件成本,不过这是在FDR中明确披露的“All other tables are replicated into 3 replicas: one full replica, one data replica and one log replica that are distributed among database nodes. A full replica contains cardinality, in-memory increments (mutations) that could be checkpointed to disk and redo log of the corresponding table. A data replica contains cardinality, checkpoints of in-memory increments (mutations) and redo log (both from the full replica). A log replica contains redo log only.” 与正常的应用在网站核心业务上3副本5副本的部署方式不同,OB在tpcc的性能测试中,3个副本不是对等的,其中1个完整副本包含redolog,LSM内存表,SST数据,这里隐含的意思是这个副本会做compaction;第2个副本只包含redolog,SST数据,它应该是在主副本完成compaction之后从主副本直接copy sst;第三副本只包含redolog。因此这里可以分析出来:整个1557台节点的内存基本都可以用于事务读写,两个副本基本没有内存开销;整个1557台节点的硬盘,用于存储2份数据文件而不是3份。之所以可以这样,是因为tpcc并没有规定或者考察RTO时间,所以只要保证RPO为零就行了。
最后,OceanBase问鼎tpcc,证明了share nothing架构是分布式数据库在性能、可用行、扩展性、强一致性上的正确路线方向,也打破了美帝在数据库行业的垄断地位,作为从业者我对这个方向充满信心,也希望其他正在做这个事的小伙伴继续努力,老板和投资人们保持长期有耐心继续投入。
![]()