两阶段提交(2 Phase Commit简称2PC)协议是用于在多个节点之间达成一致的通信协议,它是实现“有状态的”分布式系统所必须面对的经典问题之一。本文通过对比经典2PC协议,和Google工程实践的基础上,分析一种优化延迟的2PC协议。为了方便说明,本文主要针对分布式数据库中,跨域sharding的2PC方案的讨论。主要参考文献:Gray J, Lamport L. Consensus on transaction commit[J]. ACM Transactions on Database Systems (TODS), 2006, 31(1): 133-160.
-
经典两阶段提交概述
-
先来回顾下经典的2PC协议,有两个角色:一个协调者(coordinator)和若干参与者(participant),协议执行可以分为如下几个阶段:
-
预处理阶段:严格来说,预处理阶段并不是2PC的一部分,在实际的分布式数据库中,这个阶段由协调者向若干参与者发送SQL请求或执行计划,包括获取行锁,生成redo数据等操作。
-
Prepare阶段:客户端向协调者发送事务提交请求,协调者开始执行两阶段提交,向所有的事务参与者发送prepare命令,参与者将redo数据持久化成功后,向协调者应带prepare成功。这里隐含的意思是,参与者一旦应答prepare成功,就保证后续一定能够成功执行commit命令(redolog持久化成功自然保证了后续能够成功commit)。
-
Commit阶段
-
执行Commit:协调者收到所有参与者应答prepare成功的消息后,执行commit,先在本地持久化事务状态,然后给所有的事务参与者发送commit命令。参与者收到commit命令后,释放事务过程中持有的锁和其他资源,将事务在本地提交(持久化一条commit日志),然后向协调者应答commit成功。协调者收到所有参与者应答commit成功的消息后,向客户端返回成功。
-
执行Abort:prepare阶段中如果有参与者返回prepare失败或者超时未应答,那么协调者将执行abort,同样先在本地持久化事务状态,然后给所有参与者发送abort命令。参与者收到abort命令后,释放锁和其他资源,将事务回滚(有必要的情况下还要持久化一条abort日志)。
-
-
-
经典2PC的局限
-
协调者宕机:2PC是一个阻塞式的协议,在所有参与者执行commit/abort之前的任何时间内协调者宕机,都将阻塞事务进程,必须等待协调者恢复后,事务才能继续执行。
-
交互延迟:协调者要持久化事务的commit/abort状态后才能发送commit/abort命令,因此全程至少2次RPC延迟(prepare+commit),和3次持久化数据延迟(prepare写日志+协调者状态持久化+commit写日志)。
-
-
-
Percolator系统的两阶段提交
-
概述:percolator是google基于bigtable实现的分布式数据库,在bigtable单行事务的基础上,它使用全局的Timestamp Server来实现分布式的mvcc(后续专门讨论,本文不展开了);还有2PC协议来实现多行事务。由于bigtable屏蔽了数据sharding的细节,在percolator看来事务修改的每一行记录,都被看作一个参与者,事务没有区分预处理和prepare阶段,可以认为事务开始后,即进入了2PC的prepare阶段。
percolator的2PC协调者并不持久化状态,而是引入primary record的概念,将事务执行过程中修改的第一个record作为primary record,在这个record中记录本次事务的状态,而在事务执行过程中其他被修改的record里面记录primary record的key(这里我觉得priamry record保存单独的表中更优雅,否则priamry record被用户删除的话,并不好处理)。在commit阶段,先在primary record中记录事务状态(包括事务ID,mvcc版本号等),成功后,才将各个参与者的修改提交(包括持久化mvcc版本号,释放行锁等)。在事务执行过程中,如果协调者宕机,那么其他参与者可以通过查询primary record中保存的事务状态来决定回滚或提交本地的修改。
-
创新与局限:在仅提供行级事务的bigtable基础上,percolator创新的实现了多行事务和mvcc,primary record的设计简化了2PC协议中对协调者状态的维护,是一套比较优雅的2PC工程实现。但是直接构建在KV基础上的数据库事务,也存在着诸多局限:
-
底层KV屏蔽了sharding细节,且不提供交户型的事务上下文机制,对存储引擎的读写只能在一次RPC提交,使得加锁、修改、提交都必须是一次bigtable的提交操作,延迟代价是巨大的。
-
尽管primary record的设计简化了2PC的协调者状态维护,但是commit时仍然要等待primary record持久化事务状态成功后,参与者才能进行commit,这一次延迟不可避免。
-
-
-
2PC协议优化
-
通过对经典2PC和percolator实现的分析,可以得到如下几个对2PC的改进思路:
-
底存存储需要暴露sharding细节,提供以分区为单位的事务上下文管理机制,使得在预处理过程中,行锁和数据修改为内存操作,避免持久化的代价。
-
简化协调者为无状态逻辑
-
减少2PC执行关键路径上的持久化和RPC次数
-
-
优化的2PC协议:
-
预处理阶段:协调者向若干参与者发送SQL请求或执行计划,一个sharding即对应一个参与者,针对这个事务,在每个参与者中会维护一个通过事务ID索引的事务上下文,用于维护行锁、redo数据等,有必要的情况(redolog过多)下,这个阶段可能会异步的持久化redolog。
-
Prepare阶段:协调者收到客户端提交事务的请求,向各个参与者发送prepare命令,命令中携带了当前事务的参与者列表,参与者收到prepare命令后,将事务的redolog、参与者列表、prepare日志持久化后,向协调者和其他参与者发送prepare成功的消息。
-
Commit阶段:协调者收到所有参与者应答prepare成功的消息后,即向客户端返回事务提交成功;对于每个参与者,当它确认所有参与者都prepare成功后,将本地事务提交并释放行锁等资源,并异步的持久化一条commit日志,然后向其他参与者发送commit成功的消息。
-
Finish阶段:对于每个参与者,当它确认所有参与者都commit成功后,将本地事务上下文释放,并异步的持久化一条finish日志。
-
-
参与者与协调者状态转移图
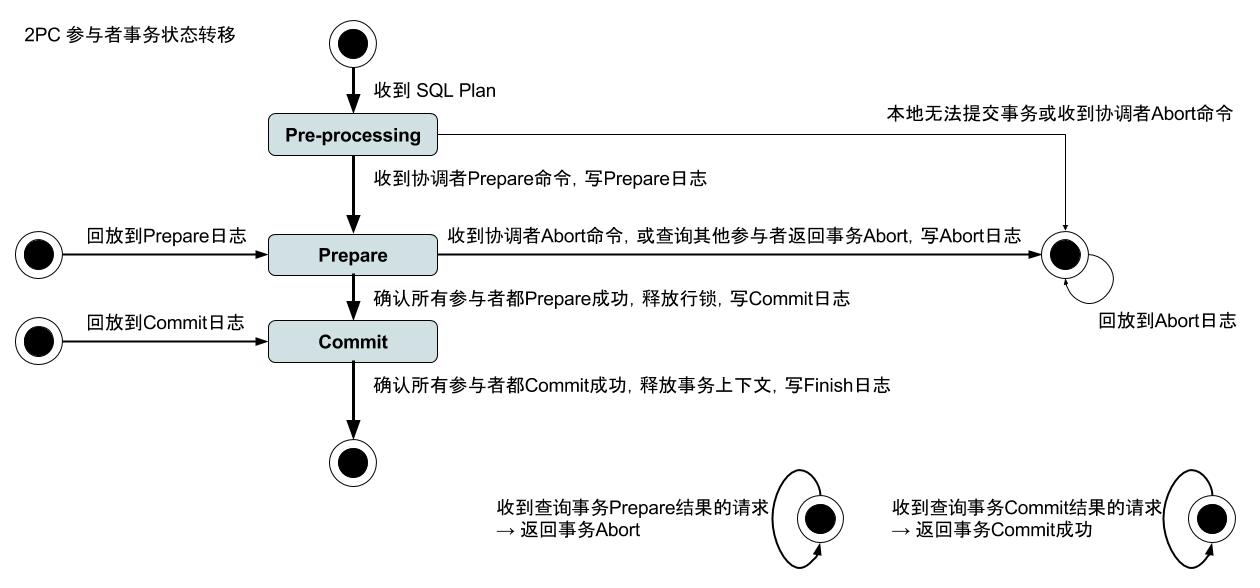
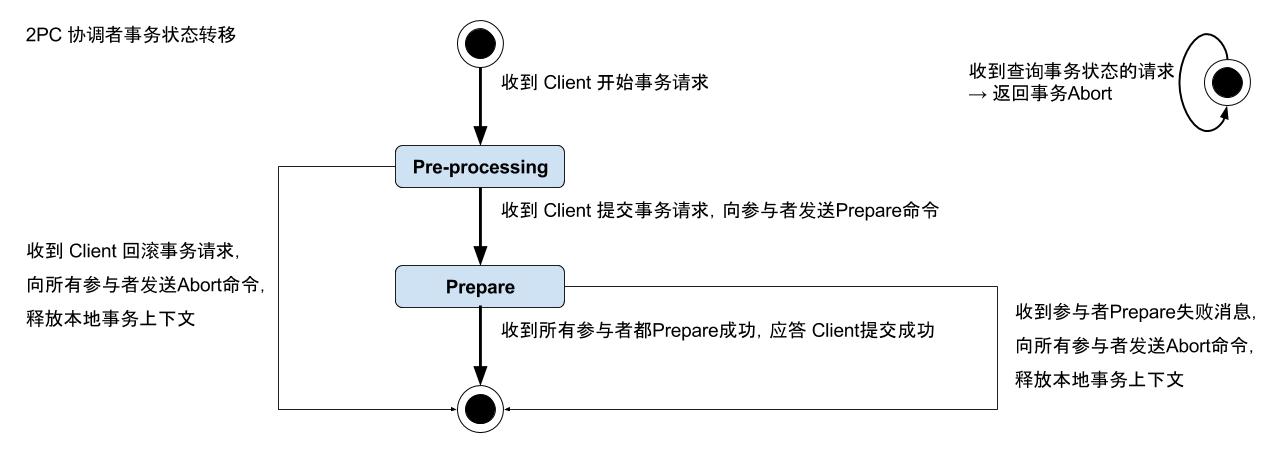
-
宕机处理与事务状态恢复要点
-
预处理阶段宕机:无论参与者还是协调者,在这个阶段宕机,事务都无法继续进行,可依靠参与者轮询协调者状态来尽快结束事务释放行锁。
-
Prepare阶段宕机:一旦所有参与者完成prepare,无论协调者是否宕机,事务最终都会被提交。对于参与者来说,如果没有持久化prepare日志,那么在回放日志时这个事务会被丢弃;如果已经持久化prepare日志,在日志回放完成后,需要向所有其他参与者查询事务状态。
-
Commit阶段宕机:这个阶段已经没有协调者的事了,所以只考虑参与者即可,如果已经持久化commit日志,那么回放日志后,它要在内存中保存这个事务状态,直到确认其他参与者都已完成commit;如果未持久化commit日志, 那么在日志回放完成后,需要向所有其他参与者查询事务状态。
-
Finish阶段宕机:同上,这个阶段已经没有协调者的事了,所以只考虑参与者即可,如果已经持久化finish日志,那么在回放过程中自然的释放事务上下文即可;如果未持久化finish日志,那么 它要在内存中保存这个事务状态,直到确认其他参与者都已完成commit。
-
事务状态的查询处理:如状态转移图所示,对于其他参与者的状态查询,在检查sharding匹配后,判断如果本地已经没有对应的事务上下文的情况下,按如下逻辑处理:
-
收到其他参与者查询Prepare状态的请求:说明对方处于prepare阶段,自己没有这个上下文,说明事务肯定已经abort,所以直接回复事务abort。
-
收到其他参与者查询Commit状态的请求:说明对方处理commit阶段,自己已经确认可以finish,说明事务肯定已经正常提交,所以直接回复commit成功。
-
-
-
延迟分析与协议局限
-
预处理阶段的redolog、Commit日志、Finish日志为异步持久化,不影响事务延迟;Prepare日志为同步持久化,需要等待持久化成功才能发送应答。参与者之间的Prepare状态与Commit状态的查询,不影响事务延迟,而协调者只需要等待所有参与者的Prepare应答后即可向客户端返回,因此协议全程只有 一次RPC交互延迟+一次日志持久化延迟。
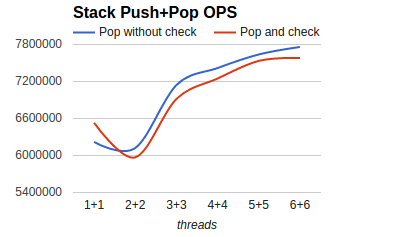
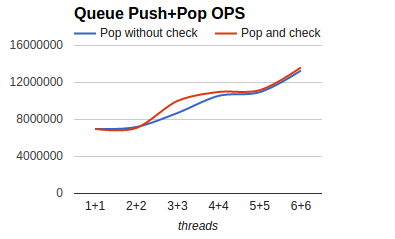
- 对读事务的影响:各个参与者上的事务,要等所有参与者Prepare成功后才能提交和释放行锁;可能出现协调者先应答了客户端,客户端再来读取时,一些sharding上的行锁还未释放(即事务还未提交),读事务需要等待直到事务提交。
-
-
![]()