-
概述
这篇文章(http://oceanbase.org.cn/?p=82)的第6小节讲述了Hazard Version的实现原理,它的设计思想最早由OB团队的席华锋提出,本文不再赘述,本文主要分享Hazard Version的实现要点,以及使用它实现无锁Stack与Queue的方法,已经在多核系统上的性能测试,代码已在github共享。
-
ABA问题
如《共享变量的并发读写》一文所述,Hazard Version主要解决的是无锁数据结构处理内存释放的问题,为此我们先来回顾一下无锁编程领域最经典的“ABA问题”,使用链表实现的无锁Stack来举例:
使用一个top指针来指向栈顶,使用CAS原子操作对top进行修改,来实现push和pop,一个常见但错误的实现可能是这样的:
void push(Node *node) {
Node *curr = top;
Node *old = curr;
node→next = curr;
while (old != (curr = CAS(&top, old, node))) {
old = curr;
node→next = curr;
}
}
Node *pop() {
Node *curr = top;
Node *old = curr;
while (NULL != curr
old != (curr = CAS(&top, old, curr→next))) {
old = curr;
}
return curr
}
push的逻辑没问题,问题在于pop,它在还未“锁定”top的情况下,就引用了top的next字段,而此时的top指向的内存空间可能已经被释放甚至重用,一方面可能直接引起非法地址访问使得程序直接崩溃;更严重的可能造成隐蔽的“ABA问题”,考虑如下时序:
-
Stack状态为 A→B →C,top指向A
-
线程I将top(即节点A的地址)赋值给curr,并取得curr→next指针(为B)放入寄存器
-
线程II执行完整pop流程,Stack状态变为B→C,top指向B,节点A被弹出后释放
-
线程II执行完整pop流程,Stack状态变为C,top指向C,节点B被弹出后释放
-
线程II执行完整push流程,新申请节点为被复用的A,Stack状态变为A→C,top指向A
-
线程I继续执行,CAS判断top值仍为A,则原子替换top为B,链表被改坏…
我们无法通过简单的修改pop逻辑来避免“ABA问题”,因为这里的纠结之处在于要“锁定(取出)”top,就要使用CAS原子的将top改为它的next指针,但是要安全的引用top→next又要先“锁定(取出)”top。因此解决“ABA问题”的根本,在于保证pop逻辑引用top指针时,它不会被释放,而在释放节点内存空间时,严格保证不会再有其他人引用这个节点。Hazard Pointer(Michael M M. Hazard pointers: Safe memory reclamation for lock-free objects[J]. IEEE Transactions on Parallel and Distributed Systems, 2004, 15(6): 491-504.)技术是一个里程碑式的创新,真正在实际工程中解决“ABA问题”(memsql/oceanbase都在使用),Hazard Version是对Hazard Pointer在易用性上的改进,原理一致,详细介绍请参考《共享变量的并发读写》一文。
-
Hazard Version实现要点和局限
-
Hazard Version设计概要

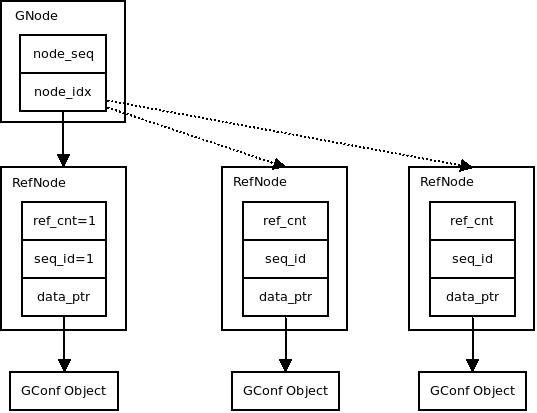
如上图所示,Hazard Version数据结构主要由三部分组成-
全局的Current Version变量
-
每个线程局部一个Hazard Version变量
-
每个线程局部一个待回收的内存块链表Retire List
Hazard Version提供如下三个操作逻辑:
-
每个线程要开始访问“可能被其他线程释放”的内存块前,将当前Current Version的值保存在线程局部的Hazard Version中,对共享内存块的操作完成后,再清除线程局部的Hazard Version值。
-
要释放一个共享内存块时,原子的将Current Version加1后,将旧值保存在内存块中,然后将它挂在线程局部的Retire List上。
-
当待回收的内存块过多时,遍历所有线程的Hazard Version,以及全局的Current Version,获得最小值(Min Version),遍历待回收的内存块,将Version小于Min Version的内存块回收掉。
-
-
获取Min Version的原子性问题
如上所述,遍历所有线程,获取Min Version的操作并不保证原子性,可能出现一个线程获取到一个很小的Current Version后,被切换出去,而错过了同时进行的遍历操作。这个问题可以通过简单的double check来规避,线程拿到Current Version,保存到线程局部的Hazard Version后,再检查一下当前Current Version是否发生变化,如果已发生变化,则重试直到Current Version不再改变为止。因为如果Current Version未发生变化,即使遍历被错过,Current Version也参加了遍历,所以得到的Min Version就是真正的Hazard Version最小值。
-
无锁遍历Retire List
回收内存时,每个线程优先回收自己本地的Retire List,如果全局待回收的节点仍然比较多,则遍历其他线程的Retire List进行回收,这里会涉及多线程操作Retire List(即它的owner线程挂入新节点,而其他线程要进行遍历),一个简单的做法是要遍历Retire List时,使用CAS将Retire List替换为NULL,取得旧值后,在当前线程本地进行遍历,对遍历剩下的节点,就挂到线程本地的Retire List上去。
-
CAS小技巧
CAS操作通常在循环中执行,一次CAS执行失败后,要重新准备新的compare参数和assign参数。比如原子修改栈顶:
Node *old_v = top; node→next = old_v; while (old_v != CAS(&top, old_v, node)) { old_v = top; node→next = old_v; }因为CAS无论成功与否,都可以返回旧值,因此这里可以用一个临时变量保存CAS的返回值,避免重新取一次top,毕竟重新取top很可能造成缓存miss:
Node *curr_v = top; Node *old_v = curr_v; node→next = curr_v; while (old_v != (curr_v = CAS(&top, old_v, node))) { old_v = curr_v; node→next = curr_v; } -
Hazard Version的局限
相对Hazard Pointer来说,Hazard Version这个本质上是管理多个线程Hazard Version的“滑动窗口”,它通过增加获取Min Version的代价,来减小各个线程获取和重置Hazard Version的代价。因此它有与“滑动窗口”一样的局限性,太久不释放的Hazard Version,会阻塞内存回收。在使用时需要注意,对Hazard Version的require和release操作之间,不能有耗时过长的逻辑。
-
Hazard Version代码仓库:
https://github.com/kayaklee/libhalog/blob/master/src/clib/hal_hazard_version.h
-
-
无锁Stack
使用Hazard Version实现无锁Stack比较简单,因为push不涉及“ABA问题”,所以只需要在pop时使用Hazard Version保护即可。
代码请参考:https://github.com/kayaklee/libhalog/blob/master/test/clib/hv_sample_lifo.cpp
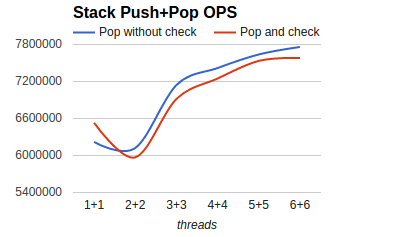
性能测试结果:如下图所示,在美团云12核虚拟机上,6个线程push,6个线程pop,不带pop结果检查情况下,最快接近780万/s的push+pop次数。
-
无锁Queue
与Stack不同,实现无锁Queue的一个难点在要维护Head和Tail两个指针,在Queue由空变为非空,和非空变为空的时候,需要保证原子的修改和判断这两个指针,这几乎是没有办法实现的。一个变通的方法,是受到Hazard Pointer论文的启发,在初始状态下,引入一个Dummy Header节点,无论push还是pop,都始终保证head和tail不会变为NULL。
这样一来,push操作不需要管head指针,每次都只修改tail即可;而pop操作,是取head→next节点中的值作为队首数据,确认head→next不为空,然后原子的将head改为head→next。因为push和pop操作都存在先拿tail或head指针,然后引用它们的next成员的操作,因此都需要使用Hazard Version进行保护。
代码请参考:https://github.com/kayaklee/libhalog/blob/master/test/clib/hv_sample_fifo.cpp
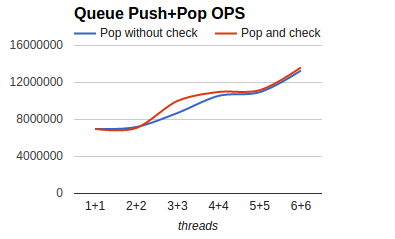
性能测试结果:如下图所示,在美团云12核虚拟机上,6个线程push,6个线程pop,不带pop结果检查情况下,最快超过1300万/s的push+pop次数。
-
Stack与Queue性能测试数据和虚拟机cpu信息:
https://github.com/kayaklee/libhalog/tree/master/test/clib/hv_performance_record
![]()